Abstract
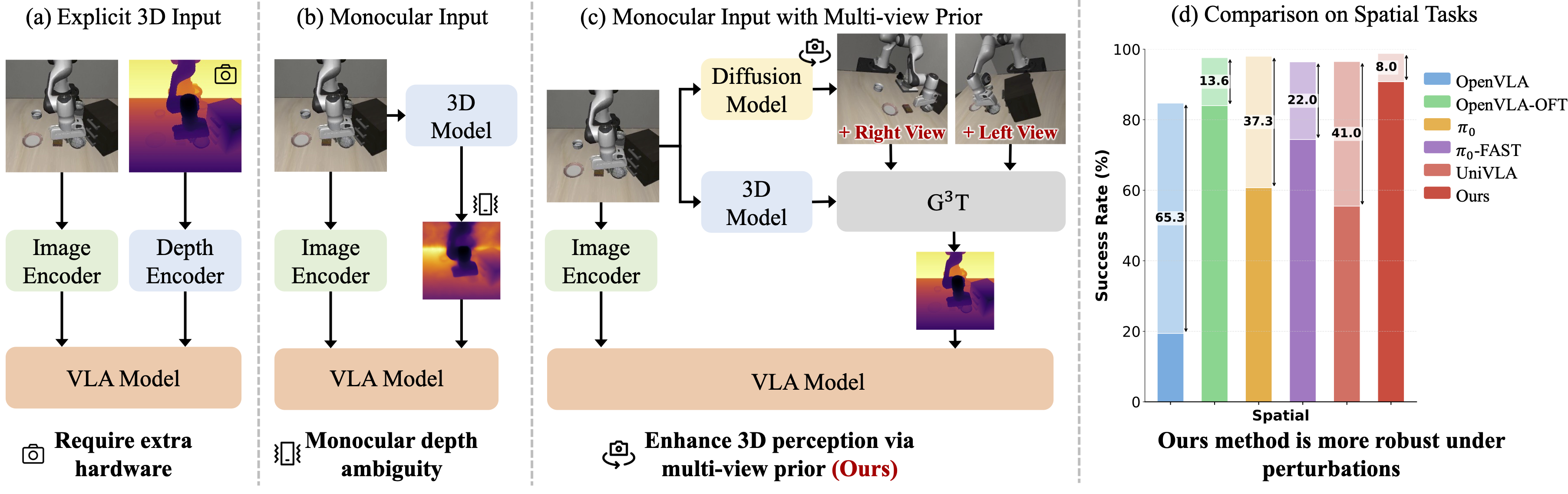
This paper addresses the challenges of spatial perception and manipulation in Vision-Language-Action (VLA) models within complex environments. While recent works have attempted to enhance VLA perception ability by injecting or distilling features from 3D foundation models, they, however, achieve only limited spatial understanding accuracy improvement, due to biased geometric predictions led by inherent depth ambiguity under monocular input conditions. Furthermore, existing action generation methods rely on indirect paradigms that predict high-dimensional noise or velocity. Regressing these unstructured targets imposes a significant optimization burden, which intensifies as the action dimensionality increases, thereby hindering the efficient learning of complex robotic policies.
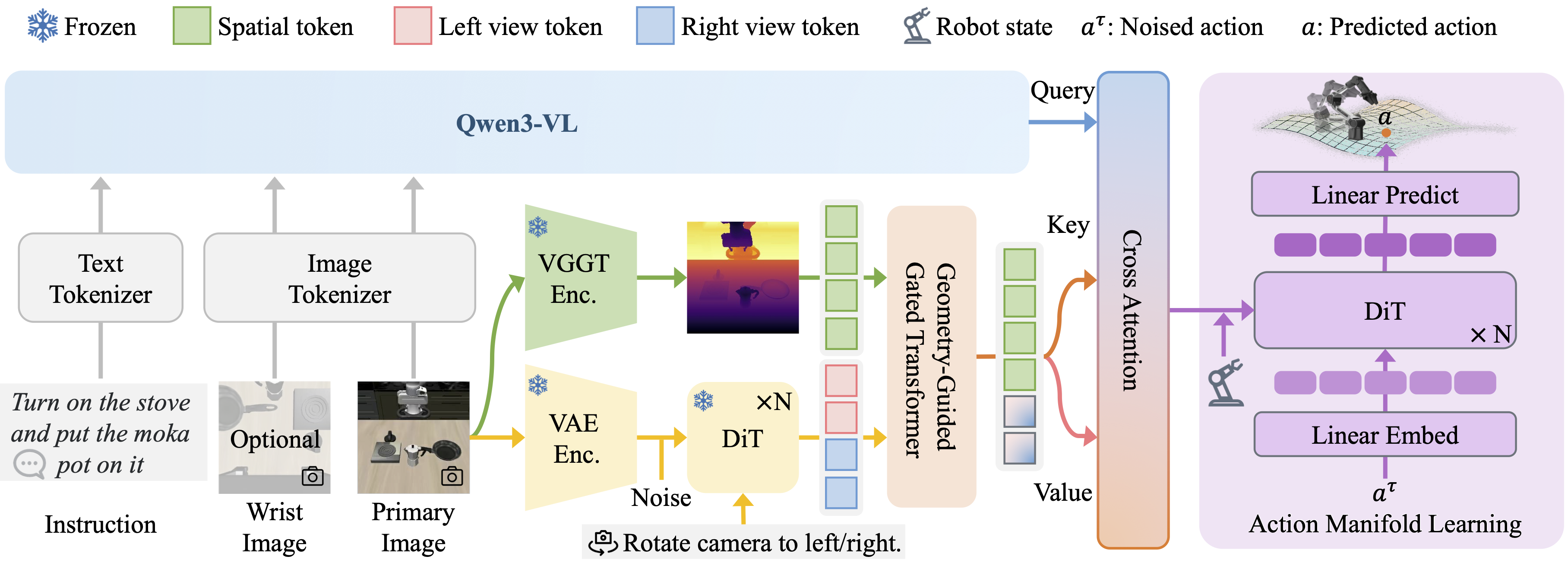
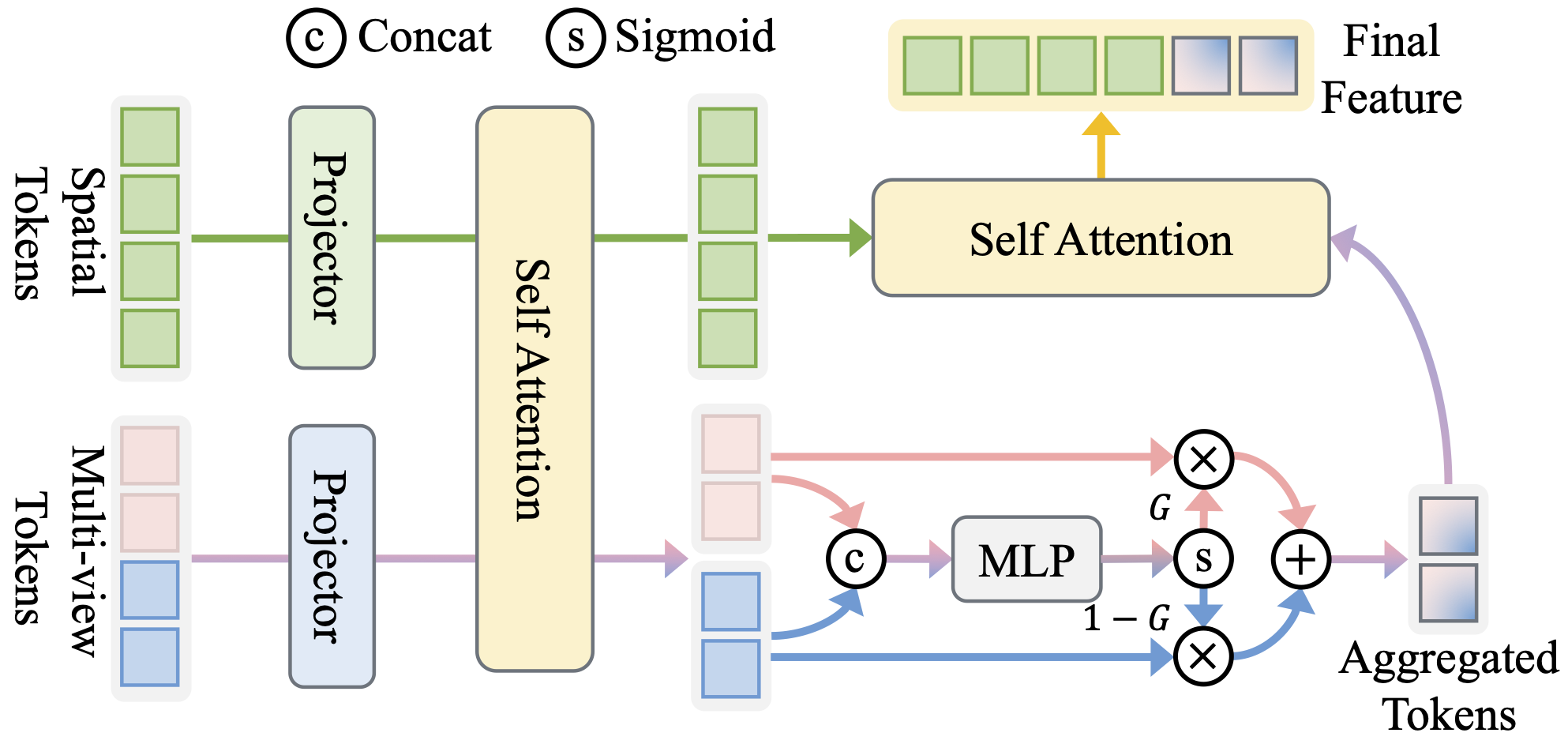
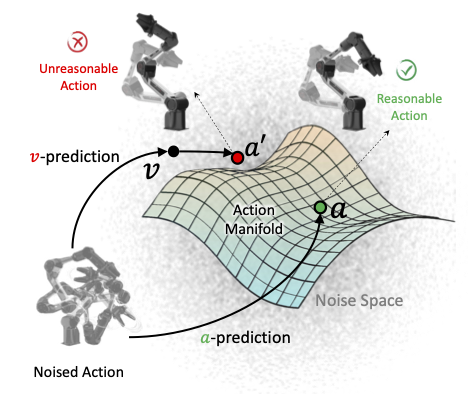
To address these issues, we present a VLA framework with the following two novel designs. First, to tackle the depth ambiguity from monocular inputs, we propose to leverage pre-trained multi-view diffusion models to synthesize novel views in latent space, obtaining enriched scene context with largely reduced geometric uncertainties. To effectively integrate these multi-view latent priors, we present Geometry-Guided Gated Transformer (G3T), which is designed to align multi-view latent features under the guidance of monocular 3D geometric priors and selectively aggregate informative views while suppressing noise from occluded regions based on an adaptive gating mechanism. Second, to overcome the optimization inefficiencies, we introduce Action Manifold Learning (AML). Unlike traditional methods that decode abstract noise or velocity, AML shifts the prediction target to direct action estimation, enabling the policy to focus on learning the intrinsic structure of valid actions for more efficient and robust execution. Extensive evaluations on LIBERO, LIBERO-Plus, RoboTwin 2.0, and real-world robot experiments demonstrate that our method outperforms state-of-the-art baselines in both success rate and robustness.